Everything We Talked About at O11yCon 2026
We just wrapped O11yCon 2026, and this year's conversations hit differently. Agent-based software development is here, now. It's no longer an optional choice, and everybody is struggling to understand what their agents are doing and how to make them cost less and perform better. Over the course of both days, we saw clearly that the old assumptions on how and who (or what) writes our software has been upended.

By: Ken Rimple

Honeycomb Innovation Week: Full Day 2 Sessions
Watch a full replay of all keynotes on Day 1 of Honeycomb's Innovation Week and learn more about what's on the roadmap for us this year.
Watch Now
We just wrapped O11yCon 2026, and this year's conversations hit differently. Agent-based software development is here, now. It's no longer an optional choice, and everybody is struggling to understand what their agents are doing and how to make them cost less and perform better. Over the course of both days, we saw clearly that the old assumptions on how and who (or what) writes our software has been upended.
Here are some highlights. We'll have videos available in the near future.
Session recaps
Scale Brilliance, Not Bottlenecks: Building Platforms for the AI-First World (Nathen Harvey, DORA/Google)
Nathen Harvey opened by sharing DORA research that should give everyone pause: AI adoption is near-universal, but outcomes vary wildly. Teams that already ship well get better. Teams that are struggling tend to feel that friction more acutely.
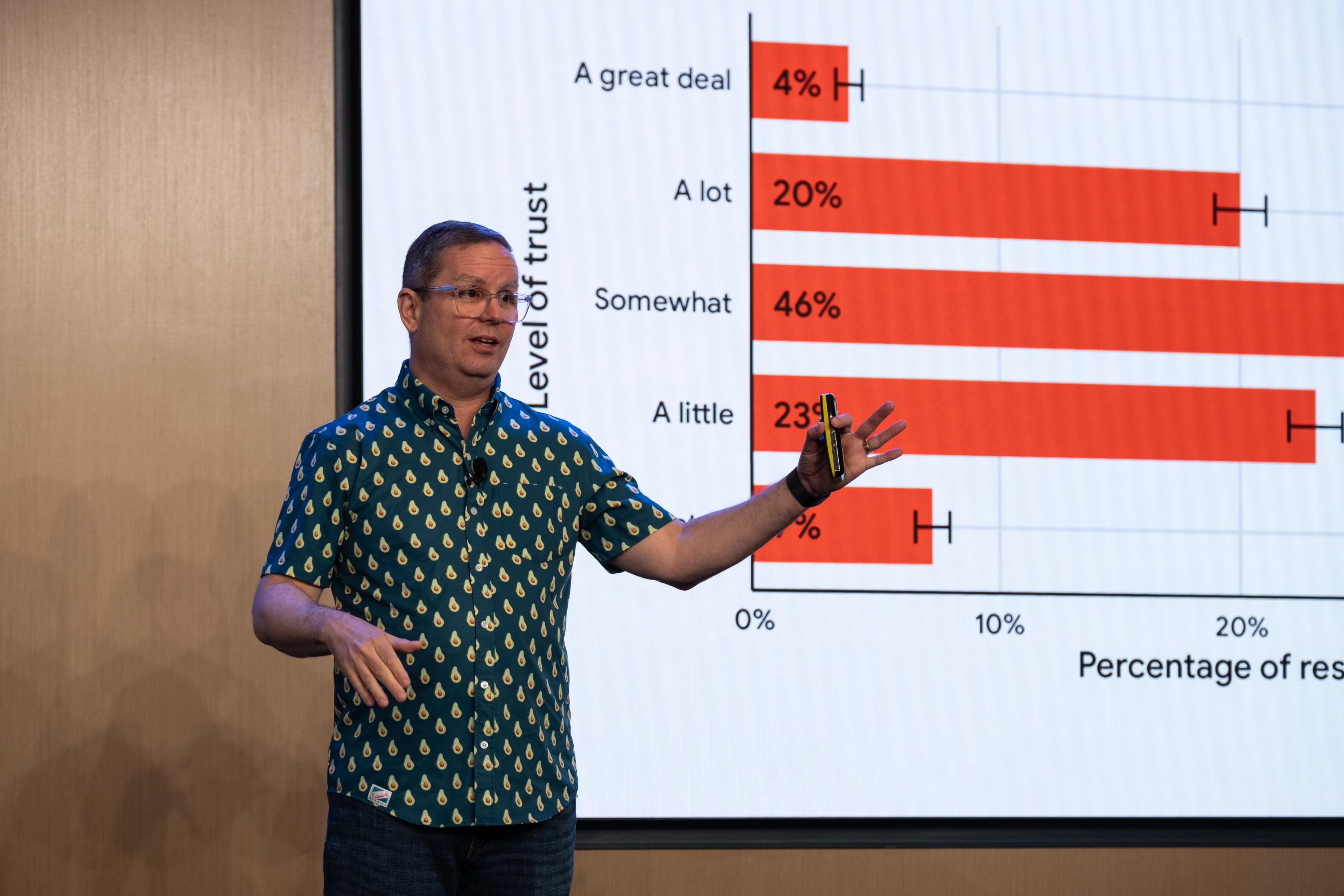
Also worth calling out: engineers are apparently hoarding what they learn about AI because they feel shame about using it, which means the knowledge that could help their teammates stays locked up. Code review is the other pressure point. PR volume is up, review time is up, and AI doesn't solve the bottleneck. Nathen’s recommendation: invest in feedback mechanisms like tests and observability rather than trying to reform review itself.
What's next at Honeycomb: Canvas and Agent Timelines (Jamie Danielson, Martin Holman, and Purvi Kanal, Honeycomb)
Our own Jamie Danielson, Martin Holman, and Purvi Kanal demoed Honeycomb's new Canvas, which, as Honeycomb alum Nathan LeClaire posted on LinkedIn, is like "Figma, Honeycomb, and ChatGPT had a baby."
One of the amazing features of Canvas is how much work the agent can do before you even open the tab. For example, when an SLO burn alert fires, an auto-investigation can start immediately; by the time you show up, there are already hypotheses and visualizations waiting for you.
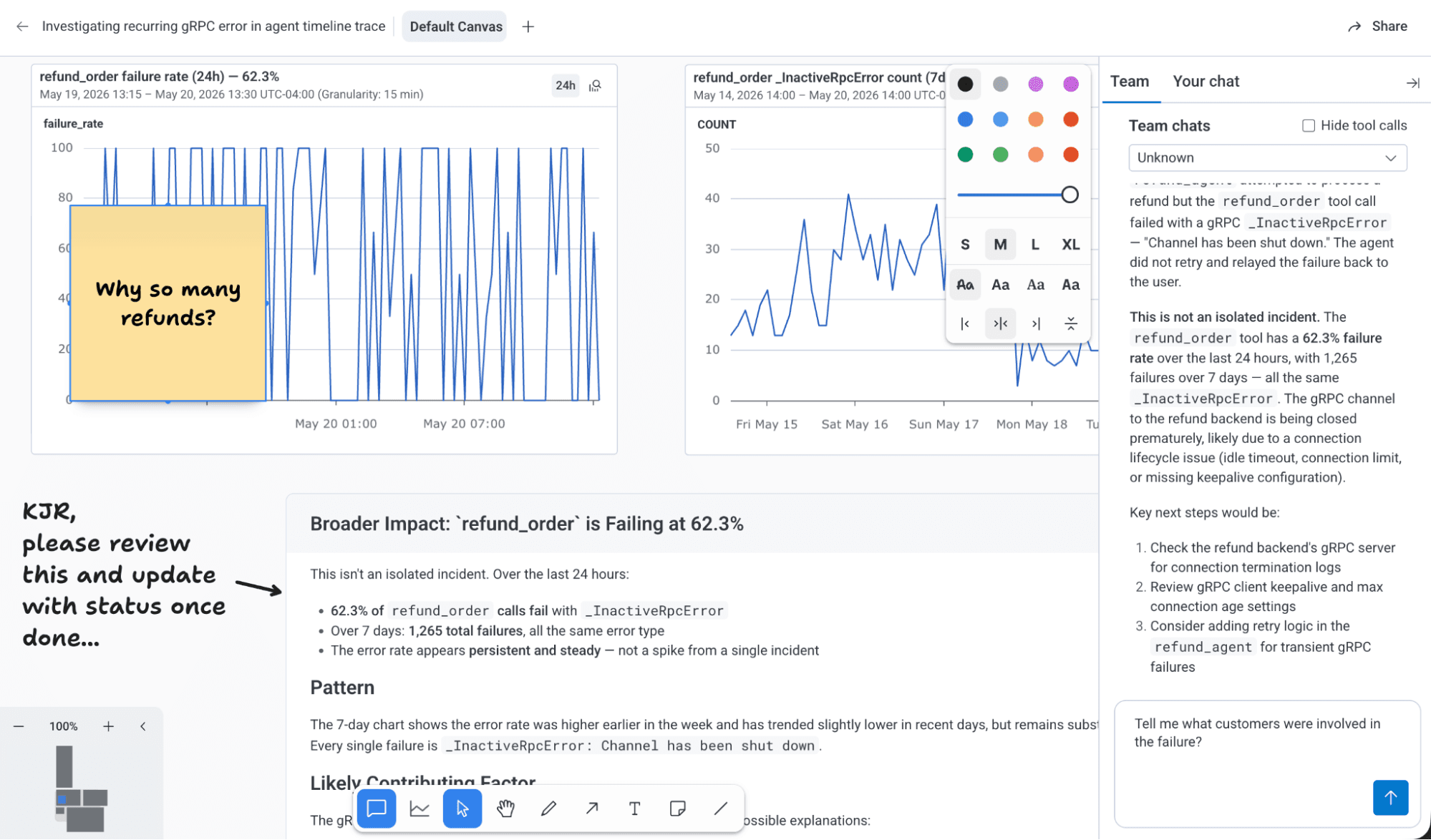
Canvas now understands OpenTelemetry GenAI semantic conventions, and can show agent invocations, LLM calls, and tool calls all in one trace view. Humans and agents can work in the same place, with skills that let each team encode their own expertise (say, Kubernetes thresholds) so both the agent and their colleagues can use it. Multiplayer support means you can see your teammates' cursors and share charts, which is a significant upgrade from Slack threads as your investigation record.

Just as important as the Canvas updates is the new Agent Timeline. Since everyone is working on agent-based applications, a single trace view won't cut it anymore. Honeycomb realized this and came up with a conversation-based view of agent interactions, and it is available from the Canvas or as a separate feature alongside traces.
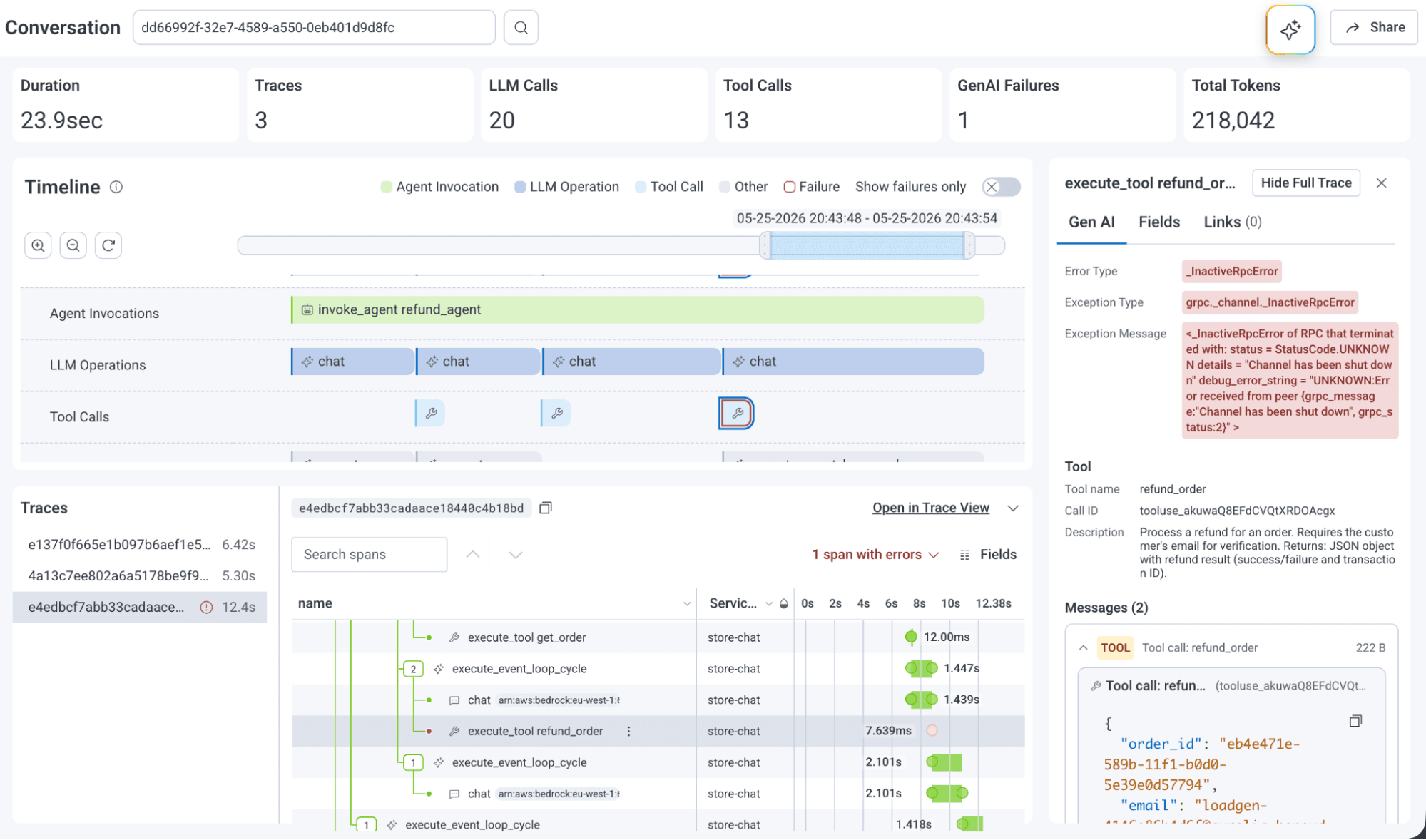
Honeycomb doesn't give you dead ends, so the team showed how easy it is to jump between a canvas, timeline, and trace. These two features captivated the audience and was the buzz of the conference.
Hangar DX Live: How Long Until We Stop Reading Code? (Ankit Jain, Aviator and Sridhar Ramakrishna, Slack)
Framed as a debate, this talk was unusually honest about where the industry actually is. PR volume is up 90-98%, review time is up 91%, and many people have already stopped doing formal review in favor of using their own LLM tools.
The core problem with LLMs as reviewers: you only see what they flagged, not what they missed. The path forward isn't abolishing review, but rethinking the division of labor: deterministic checks handle deterministic verification, humans handle judgment. And when an LLM keeps flagging the same thing, that's a signal to codify it as an actual check rather than perpetually re-explaining it.
Be Brilliant at the Basics: What AI-Era Software Delivery Demands of Engineering Leaders (Thomas Squeo, Thoughtworks)
Thomas’ message was directed squarely at enterprises trying to run before they can walk. Organizations that want to move to agentic delivery without solid CI/CD, observability, or a developer platform in place are going to struggle. Observability that only runs as a forensic exercise after an incident doesn't work as a guardrail for agents. Without platform engineering, there's no coherent place for models, evaluation, token management, and policy-as-code to live.
A culture allows as its worst behavior becomes the norm.
Thomas Squeo
Thoughtworks
Building an AI Observability Agent: Lessons from the Trenches (Rob Miles and Michael Cowgill, Stripe)
Stripe built an incident investigation agent and shared some of their experiences. The first surprise: the agent took the wrong path on a simple incident because of a service-name mismatch in the agent's context.
Another issue: the size of the logs broke the LLM's context window. This was fixed by moving logs into sub-agents that return structured summaries, rather than letting raw log data flood the main prompt.
Stripe also shared that getting evaluations right is a genuinely hard problem: agents are bad with dates, snapshots go stale, and the final 5% still requires human review.
A key finding around their incident investigation agent work was that “It's very easy to make something work, very hard to make it work really well.” It's not like the agents are going to find root causes 90% of the time right away. That depends on the quality of your data.
Stripe emphasized that using natural language interfaces via agents and pointing them to MCPs such as Honeycomb's MCP gives a quick win. It improves the life of your on-call engineers by getting better data to them quickly.
Agentic Software Development at Salesforce with Honeycomb Intelligence (Nishi Bhonsie and Maksym Bogdanov, Salesforce)
Salesforce brought a case study: a journey from having telemetry to actually having observability. The distinction they kept coming back to was "spans that were dumb." The hard work was in cataloging signals, mapping them to actual business value, and instrumenting iteratively.
Three standout moments:
- diagnosing a Bazel sync issue affecting more than 2,500 developers by adding richer spans;
- building a seven-panel dashboard from a single natural language prompt via Claude and the Honeycomb MCP server;
- using live telemetry in Canvas to surface root causes nobody had thought to look for.
The line between software engineer and SRE is blurring at Salesforce, and instrumentation is now treated as a first-class feature rather than an afterthought.
Signal vs. Spend: Building Cost-Aware Observability at Slack (Emma Montross and Steven Richards, Slack)
It started with a single log line taking up a massive amount of volume: 500 million emissions per hour. Pulling that thread led Emma and Steven into Slack's broader logging pipeline: 311 billion logs per day at 4.4M/sec peak, with no volume limits, no per-service attribution, and no feedback to the teams generating the noise.
They built a logging MCP server and a Claude skill that hunted down the worst offenders (unsampled hot paths, whole-object dumps, timer-based chatter, and logs redundant with metrics) then gave Claude source-code access so it could open PRs with the data attached rather than file tickets. To keep the problem from growing back, they added a log review agent on every PR, so engineers see the cost impact of their log changes before they ship.
This resulted in an over 30% cost reduction Slack-wide (some services hit 50%), retention extended from five to seven days, and seven-figure annual savings. The AI analysis itself cost under $500.
As Martin Thwaites put it: "Management hadn't reviewed the talk, and were in the audience. Luckily, Emma and Steven still have a job. We think the 30% cost reduction helped."

Beyond Documentation: Why Knowledge Trust Scoring Is the Next Frontier of Engineering Observability (Jody Bailey, Stack Overflow)
Bailey made a case for something the industry hasn't fully grappled with yet: it doesn't matter how good your model is if the knowledge it's acting on can't be trusted.
Inside most organizations, knowledge is fragmented across tools such as Confluence, Jira, Notion, and Google Docs, some of it years out of date. Retrieval is not the same as accuracy. The trust signals that matter for agent knowledge include source, last validation date, author expertise, conflicting information, and downstream outcomes.
If agents are going to operate in production, the knowledge shaping their decisions has to be production-grade.
Defining the Relationship: You're Not Married to Your SRE Engagement (Will Hegedus, Akamai)
Will framed SRE and development as a relationship.
Without trust, you get shadow work and slower deployments; bad SRE/dev dynamics actually make reliability worse. The best relationships have blurred lines: a great SRE can pass as a developer, and vice versa. His practical advice was to define the relationship formally before standing up an SRE team at all, which could mean a spreadsheet or even a Venn diagram on a napkin. What matters is that it's documented and revisited.
"Vulnerability gets vulnerability. The first mover creates the snowball effect."
Has AI Killed the SDLC As We Know It? (Boris Tane, David Poll, and Charity Majors, moderated by Jessica Kerr)
When we got this panel together, we knew there'd be strong opinions... but we didn't expect that three smart people would disagree productively for an hour and somehow leave the room with more questions than they walked in with. Perhaps we should have foreseen this, but either way, it was an awesome conversation.

The fight: Jessica moderated a panel that didn't reach consensus, which made it useful. Boris argued the SDLC is dead: his agent wrote 5,000 lines during the previous talk, nobody reads code anymore, the PR is a fossil. David pushed back: cheap code makes the PR more important, because what's left is judgment, taste, and "Do I want this in my product?" Charity rejected both: you can't YOLO everything to production, some things don't roll back, and friction is load-bearing.
Where they agreed: the SDLC ordering has collapsed and production is now a stage of development, not something that comes after it. Charity's best diagnosis: the PR is overloaded, one conversation forced to carry quality, taste, security, product judgment, and hurt feelings. The teams moving fastest are encoding judgment at generation time rather than review.
The real argument: code has been doing too much work. It's the only record of our specs, contracts, and intent, and that breaks when agents generate it by the thousand-line. Charity's prescription, borrowing from the strangler fig pattern: decouple intent from code so architecture is defined once and implementation is regenerated against it. David agreed that contracts are increasingly byproducts of human/agent collaboration; the open question is where that system of record lives without drifting from production.
Jessica closed with the word nobody had said yet: evals, plus higher-level artifacts (service maps, architecture diagrams) as the stable, versionable layer above generated code. Bounded non-determinism below, deterministic specification above. We got no answers, but hey, at least we asked the right questions!
Prove It: The New Bar for Observability Value (Colin Burke, Honeycomb and James Lovell, Improving)
Cost consolidation and engineering efficiency pitches don't unlock new budget anymore. The conversations that do are based on revenue.
Colin's advice was to know your audience. Engineers talk uptime and error rates, but budgets are signed based on outcomes. He advised attendees to lead with the business problem the organization is already trying to solve. James illustrated this point by telling the story of an auto lender that leveraged better instrumentation to cut underwriting from days to minutes. The competitive advantage was the story, not observability.
Making Metrics LLM-Ready: Structured Observability Data for AI-Assisted Analysis (Stephanie Wang, MongoDB)
Stephanie's talk made a case that the gap between having observability data and getting useful answers from an LLM is a data problem, not a model problem.
She identified three gaps: fragmentation across systems, raw data that's built for collection rather than analysis, and a lack of meaning (the model doesn't know whether a number is good or bad).
Her three solutions included providing a unified access layer, a standard transformation template that includes baselines and deltas, and a semantic layer that encodes directionality and thresholds.
As a side-benefit, providing these tools and approaches reduces LLM costs... She noted, "Sonnet handles this fine. You don't need Opus."
Trust, Risk, and AI: A CISO's View from the Front Lines (Giles Douglas, Superhuman)
Giles holds an unusual combined role over infrastructure and security, and his reframe of both. He argued that security's job isn't to prevent things from happening. Rather, it’s to make it safe to do things. Security should provide guardrails, not gates. Policies have to be living documents.
The four enterprise AI worries he hears most (non-determinism, trust boundaries between agents, data egress, and shadow IT/wallet trails/identity swaps) are not new. AI just accelerates them.
He remarked that capturing prompts is not that hard. Capturing agent tool calls is more of a challenge.
OpenTelemetry's value in this context is modeling relationships and lateral movement.
Velocity is underrated as a challenge: Anthropic ships something new most Wednesdays.
Socratic AI: Integrating Observability through Interactive Dialogue (Bryan Mills, Duolingo)
Bryan identified three failure modes in AI-assisted production investigation: missing context, fallible memory (forgetfulness and hallucination), and lack of rigor (smoking-gun thinking, sycophancy). He pointed out these are the same failure modes humans have.
The fixes are familiar, but adapted: provide checklists for context, structured note-taking for memory, citation and provenance for hallucination, peer review for rigor.
His specific advice for when an agent gets something wrong: don't tell it the answer. Ask questions. Let it collect more evidence and convince itself. Treat "confirm" and "refute" as equally useful inputs.
Survivable by Humans, Uninhabitable by Machines: Is Your Production Environment Ready for AI? (Rick Clark, UST)
Rick argued that the modern enterprise operating model rests on three premises:
- behavior is determined by code
- bugs are defects against a knowable spec
- the artifact you tested is the artifact you deployed
They happen to be ones that AI breaks.
With agentic AI, behavior emerges at runtime from model weights, prompts, tool graphs, and retrieval context. An agent can return an HTTP "200 OK" response quickly while also doing the wrong thing.
Clark introduced the term "behavioral observability," which is a measurement for whether the system is acting outside its normal pattern. Our operational stacks have almost no vocabulary for this yet.
The Three Pillars of Observability: Traces, and Two Things My Agents Never Look At (Corey Quinn, closing keynote)
"The runbook lost. The trace is the documentation now."
Corey opened with a billing question to Anthropic that got a technically correct answer amounting to "figure it out yourself."
The animating question of the talk: what does observability look like when the primary reader isn't a person? Metrics are a dead end for agents (the aggregate destroys the path). Logs are what you write when you've given up on structure. Traces are the front door. The practical implication: span names and attribute names are an API. The agent consuming them can't ask clarifying questions. Treat them like a public schema, version them, write a changelog when you rename something, and stop letting whoever last touched the file rename user_id to userid.
Come for the talks, stay for the ideas
The theme threading through running through all fifteen talks was pretty consistent: the assumptions we built our practices on are getting stress-tested in real time, and the teams doing well are the ones paying close attention to what's actually happening in production.
If any of this sparked something for you, or if you want the foundational theory that makes all of it click, pick up a copy of Observability Engineering.