Meet the Author

Charity Majors
CTO
Charity Majors is the co-founder and CTO of honeycomb.io. She pioneered the concept of modern Observability, drawing on her years of experience building and managing massive distributed systems at Parse (acquired by Facebook), Facebook, and Linden Lab building Second Life. She is the co-author of Observability Engineering and Database Reliability Engineering (O’Reilly). She loves free speech, free software and single malt scotch.
Explore Author's Blog


Production Is Where the Rigor Goes
In early February, Martin Fowler and the good folks at Thoughtworks sponsored a small, invite-only unconference in Deer Valley, Utah—birthplace of the Agile Manifesto—to talk about how software engineering is changing in the AI-native era. The longer I sit with this recap, the more troubled I am by what it doesn't say. I worry that the most respected minds in software are unintentionally replicating a serious blind spot that has haunted software engineering for decades: relegating production to the realm of bugs and incidents.

Honeycomb 10 Year Manifesto: Observability in a World of AI-Generated Code
When we left Facebook, we were determined to build a tool that would help solve the hardest problems in software. Not by copying everyone else’s architectural hand-me-downs and making incremental improvements, but by borrowing from powerful BI and product tools, and reasoning from first principles about what software engineers need to understand their code in production.




How Much Should I Be Spending On Observability?
In last week’s piece, we talked about some of the factors that are driving costs up, both good and bad, and about whether your observability bill is (or should be) more of a cost center or an investment. In this piece, I’m going to talk more in depth about cost drivers and levers of control.

How Much Should I Be Spending On Observability?
In 2018, I dashed off a punchy little blog post in which I observed that teams with good observability seemed to spend around ~20-30% of their infra bill to get it. I also noted this was based on absolutely no data, only my own experiences and a bunch of anecdotes, heavily weighted towards startups and the mid-market tech sector.

Welcome Jessica Nunn To Our Board of Directors!
Ever since January of 2022, we have had an employee representative seated on our board of directors. Paul Osman was the first employee to hold the position; when he left the company, Alyson van Hardenburg took over and filled out the rest of his time; we then nominated her to serve another year in that seat.
There Is Only One Key Difference Between Observability 1.0 and 2.0
We’ve been talking about observability 2.0 a lot lately; what it means for telemetry and instrumentation, its practices and sociotechnical implications, and the dramatically different shape of its cost model. With all of these details swimming about, I’m afraid we’re already starting to lose sight of what matters. The distinction between observability 1.0 and observability 2.0 is not a laundry list, it’s not marketing speak, and it’s not that complicated or hard to understand. The distinction is a technical one, and it’s actually quite simple.
It’s Time to Version Observability: Introducing Observability 2.0
In 2016, we at Honeycomb first borrowed the term “observability” from the wikipedia entry for control systems observability, where it is a measure of your ability to understand internal system states just by observing its outputs. We then spent a couple of years trying to work out how that definition might apply to software systems. Many twitter threads, podcasts, blog posts, and lengthy laundry lists of technical criteria emerged from that work, including a whole ass book.

The Cost Crisis in Metrics Tooling
In my February 2024 piece The Cost Crisis in Observability Tooling, I explained why the cost of tools built atop the three pillars of metrics, logs, and traces—observability 1.0 tooling—is not only soaring at a rate many times higher than your traffic increases, but has also become radically disconnected from the value those tools can deliver. Too often, as costs go up, the value you derive from these tools declines.
The Cost Crisis in Observability Tooling
The cost of services is on everybody’s mind right now, with interest rates rising, economic growth slowing, and organizational budgets increasingly feeling the pinch. But I hear a special edge in people’s voices when it comes to their observability bill, and I don’t think it’s just about the cost of goods sold. I think it’s because people are beginning to correctly intuit that the value they get out of their tooling has become radically decoupled from the price they are paying.

LLMs Demand Observability-Driven Development
Many software engineers are encountering LLMs for the very first time, while many ML engineers are being exposed directly to production systems for the very first time. Both types of engineers are finding themselves plunged into a disorienting new world—one where a particular flavor of production problem they may have encountered occasionally in their careers is now front and center.

We Did it Again: We’re a Leader in 2023 Gartner® Magic Quadrant™ for APM & Observability for the Second Year in a Row
When the Gartner Magic Quadrant Report came out in 2022, we did the professional equivalent of a spit take, then cheered wildly. NOT ONLY did they include observability for the first time ever in their newly revamped 2022 Magic Quadrant for APM & [now] Observability, but they also put us in the Leader Quadrant—our debut appearance!
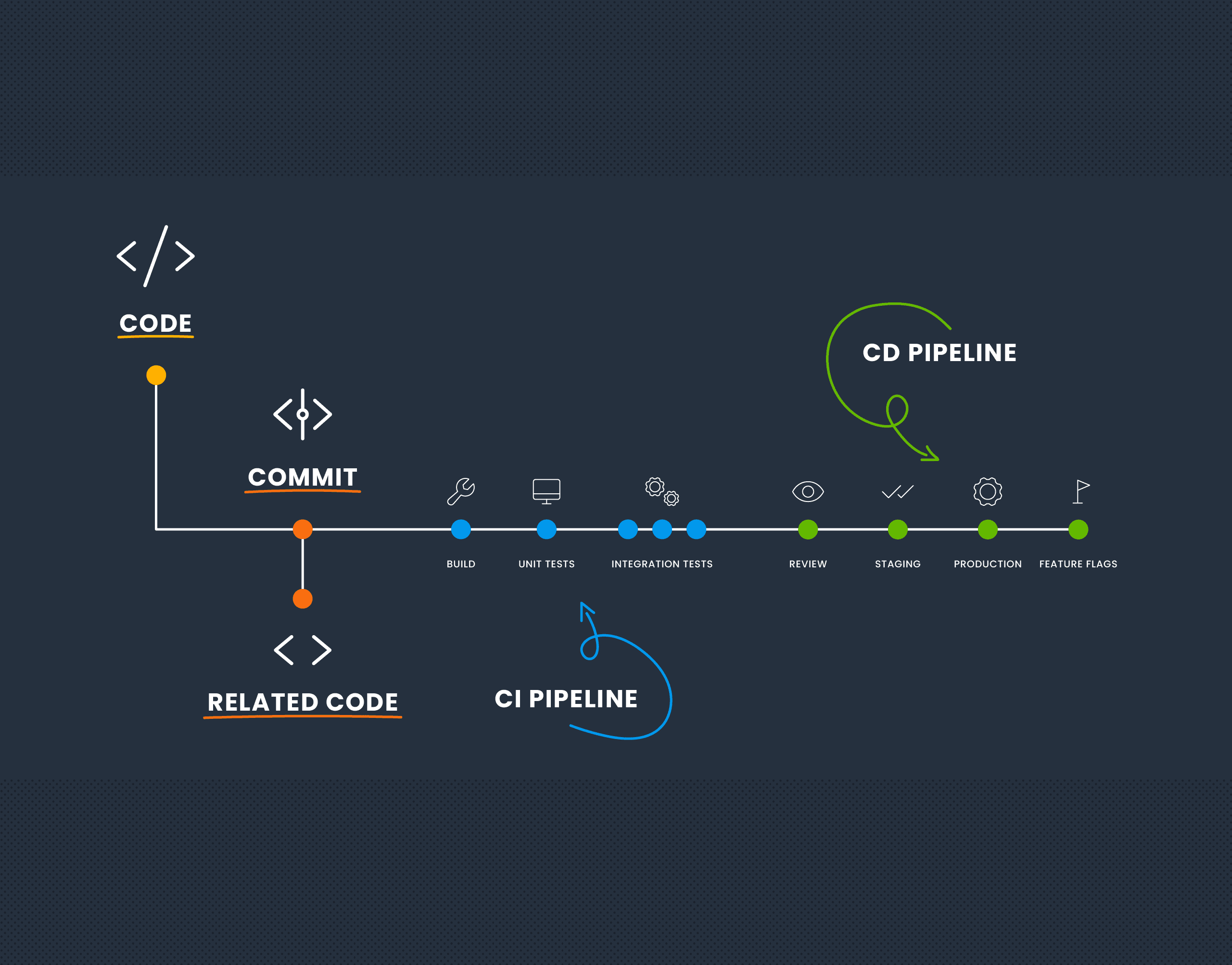


The Future of Ops Is Platform Engineering
In the beginning, there were people who wrote and ran software. At some point, we spun away ops skills from dev skills into two different professions, but that turned out to be a ginormous mistake, so along came DevOps to reunify them. Nowadays, ops as an independent profession is in the process of fading out. Companies are spinning down their ops teams left and right. Engineers who formerly identified as sysadmins or operations have turned into DevOps engineers, and soon there will just be “software people” again. This is the way of things.